Stable Diffusion免安装一键启动保姆级教程,LoRA模型生成大长腿AI女友
推广
| 推荐 | 链接 | 教程 |
|---|---|---|
| 翻墙机场VPN | 注册链接 | 不限时翻墙机场推荐,众多不限时套餐|大流量套餐|免费试用|畅享4K |
| SuPay虚拟U卡 | 注册链接 | 【视频教程】-SuPay美元虚拟U卡,支持ChatGPT Plus订阅,覆盖99%支付订阅场景 |
| 欧易开户教程 | 注册链接 | 【视频教程】-币圈小白入门,从零开始购买加密货币,欧易如何交易加密货币? |
背景
我相信大家都对对鼎鼎大名的Stable Diffusion AI画图有所耳闻,但是不知道大家有没有自己使用过,因为Stable Diffusion的确有一定的使用难度,光是安装的复杂度已经各种奇奇怪怪的报错就让大部分人望而却步。
今天我来教大家使用打包好的Stable Diffusion启动器,一键启动Stable Diffusion WebUI,并使用LoRA模型来生成你的大长腿女友。
这篇教程是纯小白教程,让你从零基础使用Stable Diffusion,可以跟着我的教程通过修改参数能生成你满意的图片。
效果
可以看一下这里面是我生成的图片效果。

下面是我的输出文件夹。
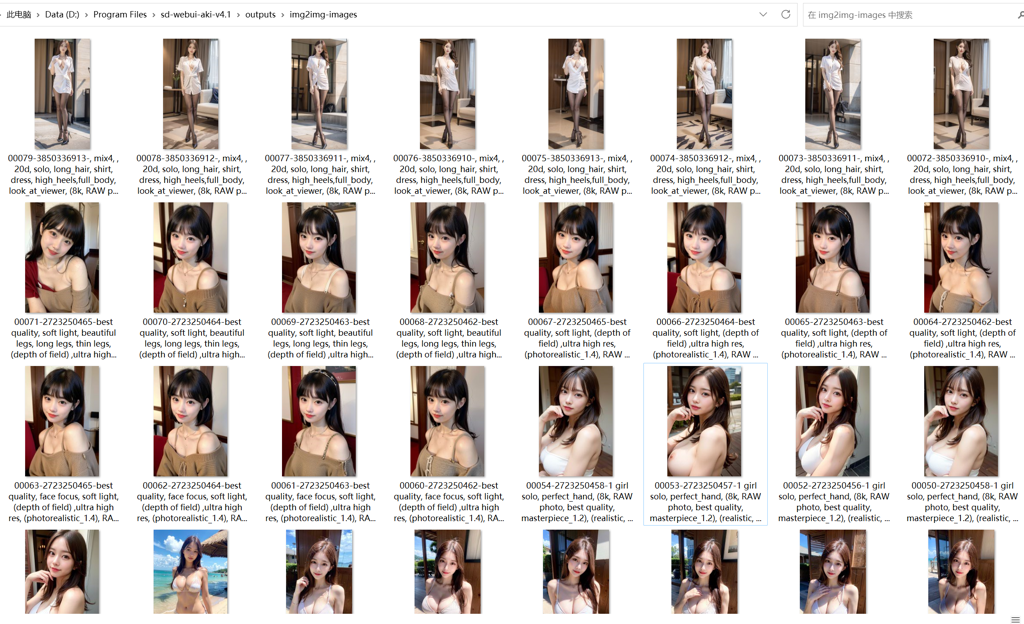
我下面来教大家轻松下载Stable Diffusion一键启动,并使用LoRA模型画出你想要的AI大长腿女友。
安装
前置条件
Stable Diffusion在本地安装,需要一定的电脑配置。
需要Windows10或者Windows11系统,显卡要是N卡,也就是英伟达显卡, SSD固态硬盘。至少是GTX1050及以上,我是GTX4050,配置越好,生成图片速度越快。
下载一键启动包
直接在此链接下载stable diffusion webUI一键启动包,这个启动包帮我们把所需依赖打包好了,我们直接下载就可以直接启动使用,无需安装。 懒人安装包下载地址
这个一键启动包非常大,有10G。
启动
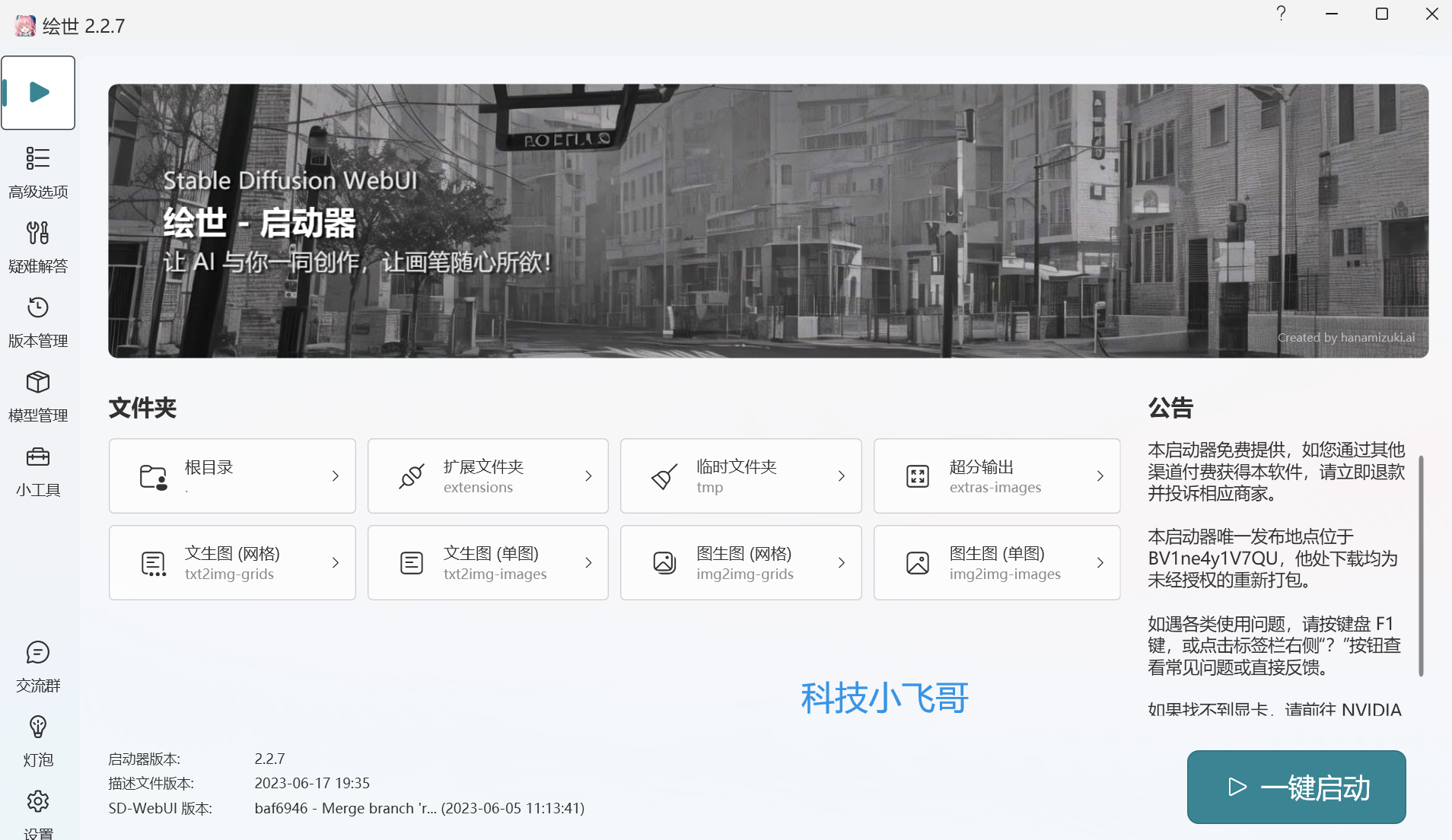
你可以选择一个盘解压,解压完成之后,进入到根目录,然后找到A启动器点击就可以启动,稍等片刻后就可以进入到启动器,我们先看看这里面有什么东西。
- 高级选项:可以配置一些硬件配置之类的,有性能设置,网络设置等等,一般来说不需要调整。
- 版本管理:启动器有最新的更新会自动同步到这里,我们一般切换到最新版本就好了。
- 模型管理:里面有不少SD模型还有Lora模型,有兴趣可以直接下载使用,我这里示范是从互联网上下载比较流行的模型使用,暂时不适用它的模型。
- 小工具:就是一些相关链接
我们回到一键启动菜单,点击右下角的一键启动。
点击后会进入控制台,然后安装必要的依赖。
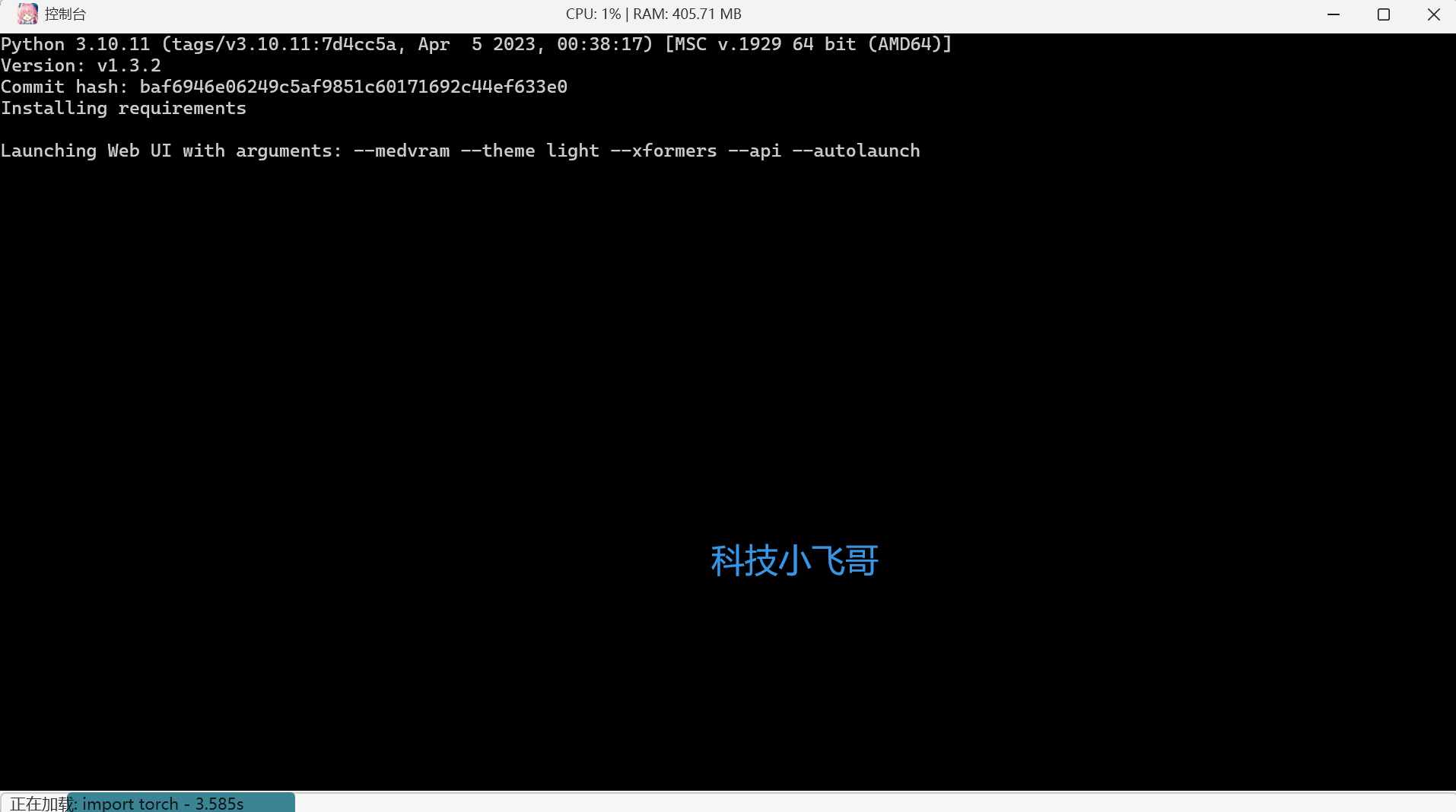
安装完成后会自动浏览器打开stable diffusion webUI界面,我们就在这里进行AI绘图。
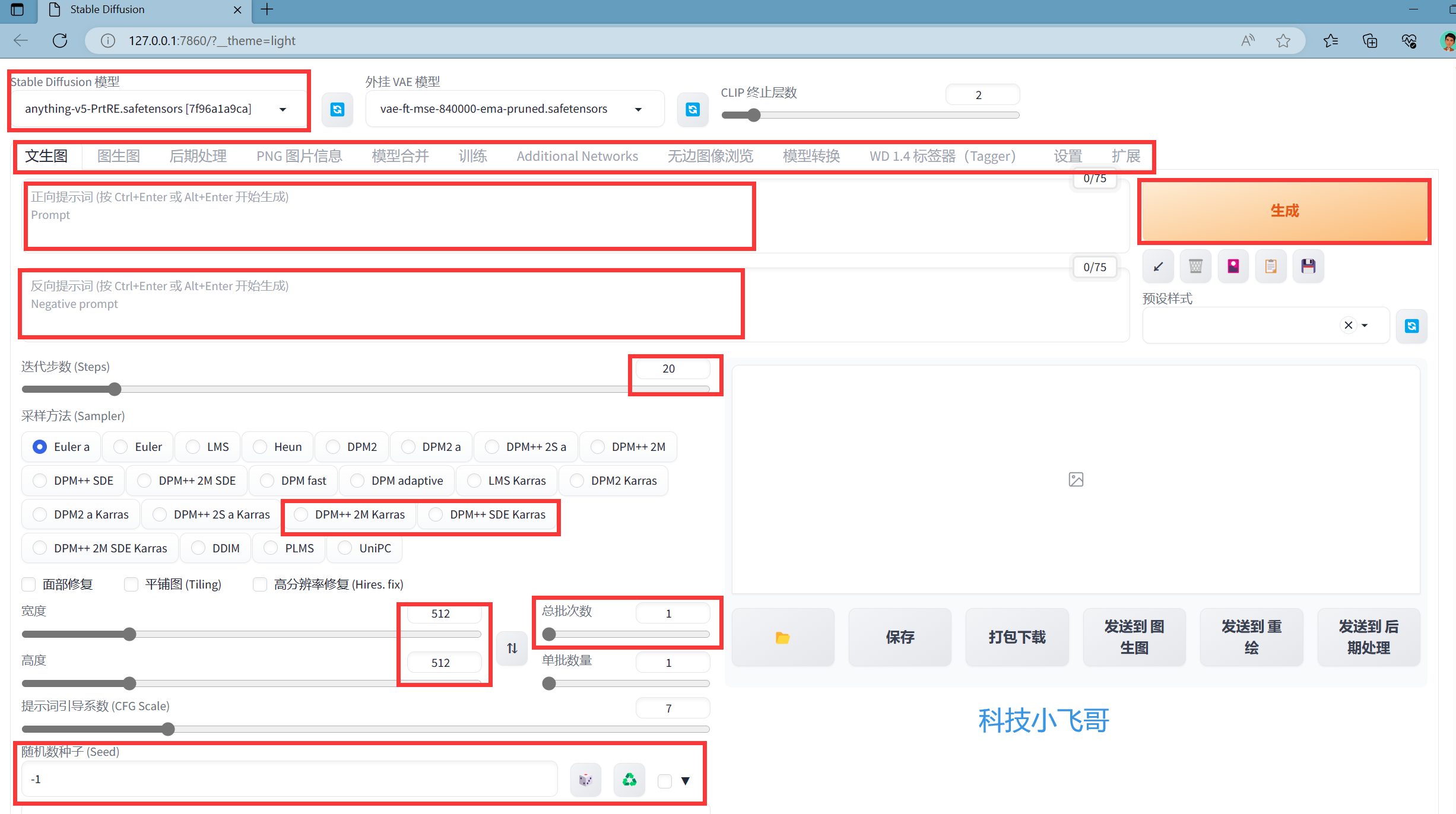
功能介绍
我先简单介绍一下: Stable Diffusion模型:就是选择Stable Diffusion的大模型,默认只有一个模型,一会我教大家下载最常用的ChilloutMix模型使用,是一个比较火的写实风的模型,大概大部分网图都是在这个模型上来的。
第二行是功能列表,最常用的就是文生图,图生图,后期处理等。
下面是正向提示词和反向提示词,正向提示词就是你的画图里面要包含的关键字,反向提示词里面是你的AI画图里面不能包含的关键字。
右边是生成按钮,当所有的参数设置好了之后就可以点击生成了。
下面是迭代步数,指的是Stable Diffusion生成图像所需的迭代步数。每增加一步迭代,都会给AI更多的机会去比对提示和当前结果,并进行调整。更高的迭代步数需要更多的计算时间。但高步数并不一定意味着更好的结果。当然,如果迭代步数太少,会降低生成图像的质量。一般20-30即可。
下面是采样方法,我就不详细介绍了,有兴趣可以看我的个人网站的完整介绍,一般来说使用DPM++ 2M Karras或者DPM++ SDE Karras并把步数设为30,得到的效果是最好的:
- Euler a:10步开始成型,但20步时的五官还是有瑕疵,30步就没什么问题了。
- Euler:10步开始已经不错,但五官有问题,20步已经没什么问题,往后看不出变化。
- LMS:到30步还是十分抽象,色块较多。
- Heun:10步开始成型,五官有瑕疵,20步效果没问题,30步主体细节上有变化。
- DPM2:10步开始成型,五官有瑕疵,20步效果没问题,30步背景细节上有变化。
- DPM2 a:都比较抽象,而且整体变化很大。
- DPM++ 2S a:10步开始成型,20步和30步效果都不错,而且画面变化幅度不少。颜色饱和度较低。
- DPM++ 2M:10步的色块还是挺严重,20步基本成型,30步的细节有了进一步的提高。
- DPM++ SDE:10步开始定型,20步成型,30步背景变化和主体细节增加。
- DPM fast:抽象派大师
- DPM adaptive:10步已经做好了,后面变化十分微小。
- LMS Karras:到30步还是有点挣扎。
- DPM2 Karras:10步还是有点抽象,20步成型,30步的主体细节又有了变化。
- DPM2 a Karras:10步还是很抽象,20步继续走样,30步成型但脸部还是有点崩。
- DPM++ 2S a Karras:10步的脸和颜色都不对,20步开始成型,30步细节上又有了变化,整体颜色饱和度低
- DPM++ 2M Karras:10步还是有点破碎,20步基本成型,30步在背景细节上有变化。
- DPM++ SDE Karras:10步虽然颜色不对,但除了脸都挺成熟了,20步成型,30步细节进一步加强。
- DDIM:10步成型,20步仍有微瑕,30步成熟。
- PLMS:一个逐步迈向现实的抽象派大师。
面部修复,平铺图,高分辨率修复,需要可以勾选。
长宽尺寸: 长宽尺寸并非数值越大越好,最佳的范围应在512至768像素之间。如果不希望主题对象出现重复,应在此范围内选择适当的尺寸。如果您需要更高分辨率的图片,建议先使用SD模型生成图片,然后再使用合适的模型进行upscale。
总批次数,就是一次性生成几张图片,一般来说选4张或者9张,看你的电脑性能,我一般选4张。
随机种子,点击筛子就是设置为-1,从头开始训练,使用右边这个按钮就是使用上次的种子继续调整,一般我们遇到合适的图片继续生成图片的时候会使用上次的种子。
生成按钮下面的几个,鼠标放上去都有中文提示,还挺有用的。
第一个就是从提示词或者上次生成的图片生成参数,一会会用到。 第二个就是清空提示词 第三个是显示扩展模型,我们Lora模型就属于扩展模型,一会会使用它来加载。
绘图
下载模型插件
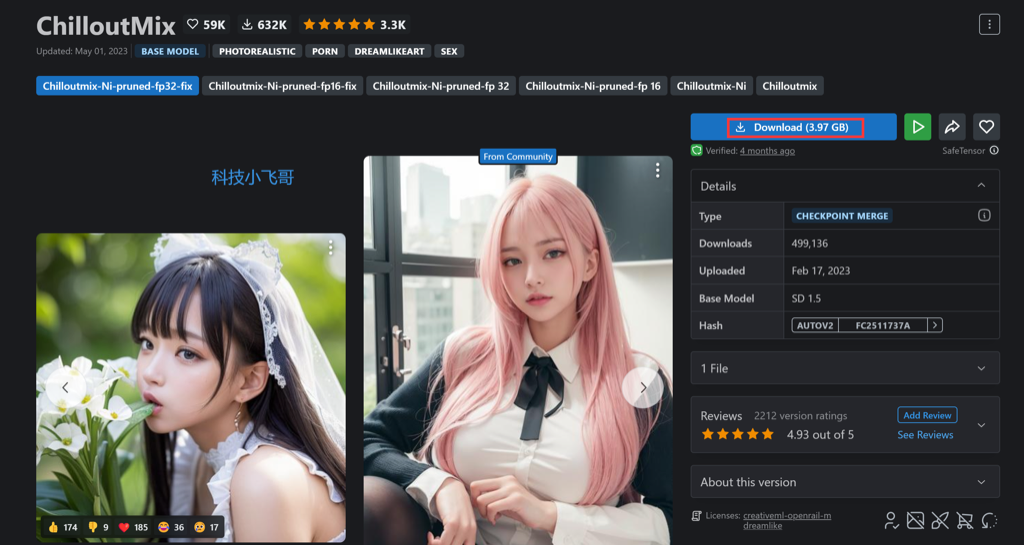
先下载ChilloutMix大模型,我们刚才说了,ChilloutMix是一个比较火的写实风的模型,大概大部分网图都是在这个模型上来的。
直接使用Google账户登陆即可。
使用这个链接打开模型:https://civitai.com/models/6424/chilloutmix
下载 ChilloutMix 大模型,3.97GB,大模型非常大。
然后把下载好的SafeTensor格式的模型,放到SD根目录的models/Stable-diffusion文件夹,这是SD大模型的文件夹。
然后打开stable diffusion的webui,也就是浏览器按钮,点击左上角模型右边的刷新按钮,刷新成功后刚才下载的模型就在里面了,选择刚下载的Stable Diffusion模型。
下载Lora模型
LoRA模型属于微调模型,是Stable Diffusion的插件,我们直接回到刚才的 https://civitai.com 的网站,右边的过滤按钮选择LoRA,然后在搜索框输入你想搜索的关键字,目前很多过于暴露的模型都被隐藏了,搜索是搜不到的,需要链接访问,等后续你熟悉了可以自己成为老司机,自己训练自己的模型。
我们搜一点正常的,就搜cute_girl吧。然后找到这个cute_girl_mix4的图,点击进去。
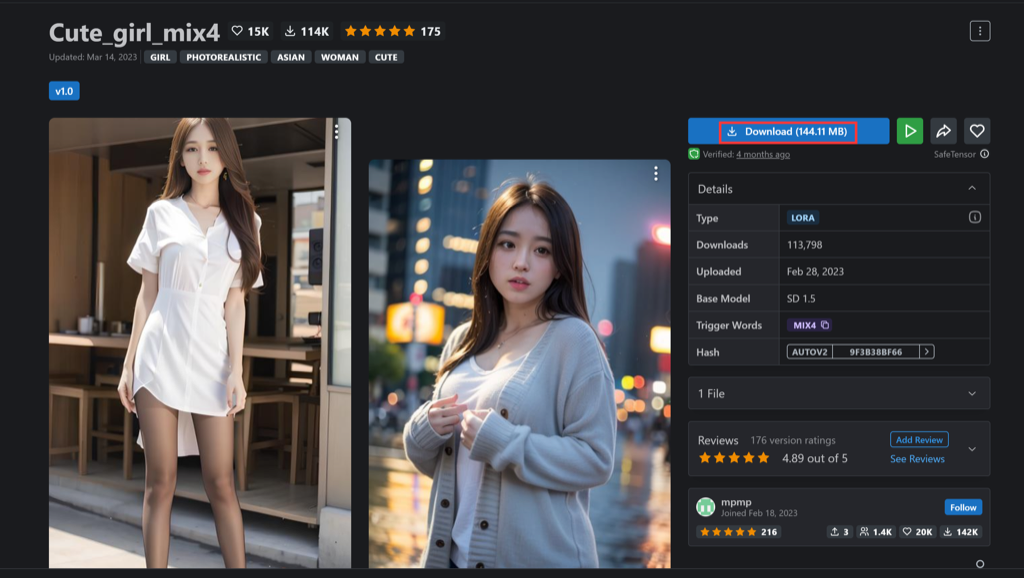
右边点击Download可以下载这个LoRA模型。我们文生图就可以基于这个LoRA模型加一些关键字来生成我们想要的图像。
惊喜的发现下面还有一个LoRA模型,点进去一看,是黑丝的LoRA模型,意外之喜,赶紧也下载下来。我们是可以同时使用多个LoRA模型并分别配置权重来生成图片的,所以你可以选择多个你喜欢的LoRA模型下载。
加载Lora模型
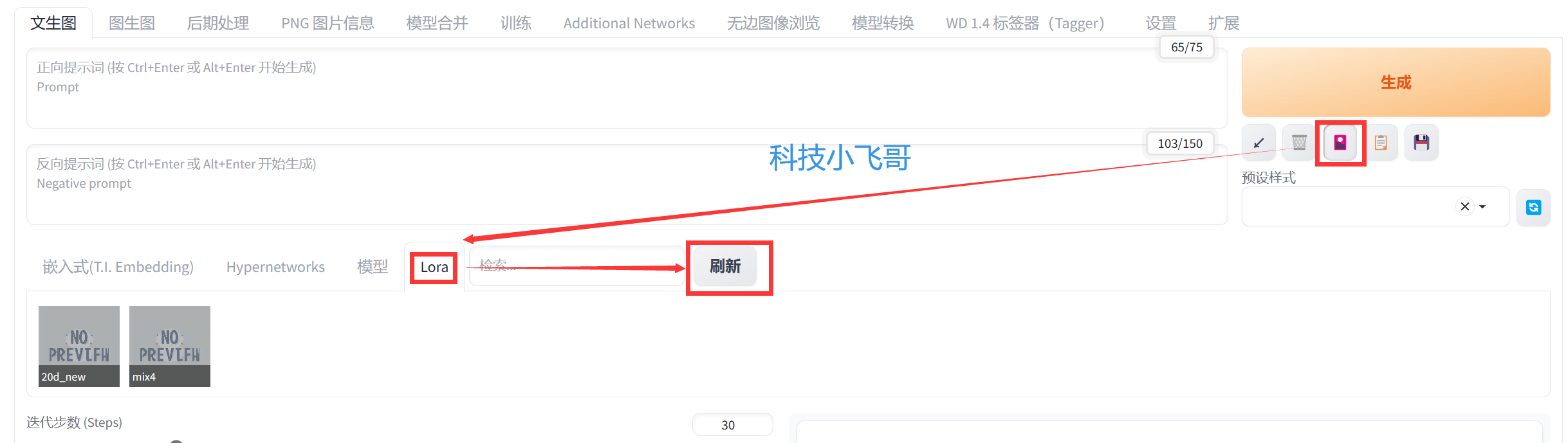
下载完Lora模型之后,然后选择SD根目录,选择 models/lora 目录把模型放进去,在webui点击右边的的生成按钮下方的扩展图标,然后选择Lora,点击刷新,刚下载的几个模型就出来了。然后再点击一下扩展图片,隐藏掉这个UI。
提示词
下一步我们就可以开始通过Lora模型+关键字来进行文生图了。如果你不会填关键字怎么办?没关系,我们先用 civitai.com 的提示词先生成图片,然后自己修改关键字来进行调整即可。
回到刚才我们下载Lora模型的这个界面,点击图片右下角的图标,提示词就自动出来了。
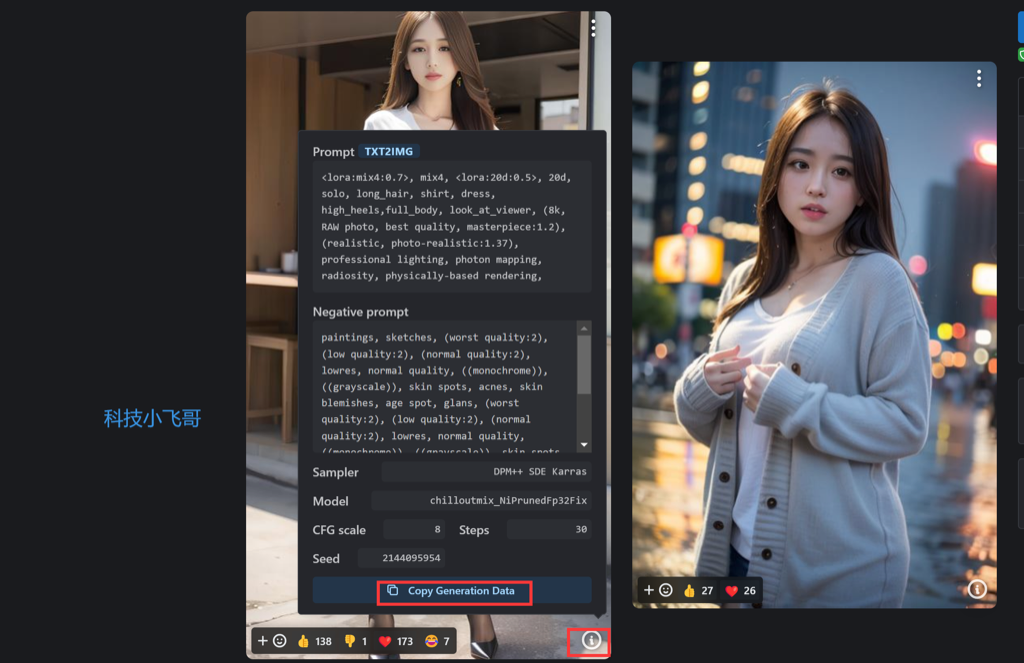
直接点击 Copy Generation Data全部复制,把内容全部粘贴到正向提示词框里面,然后点击一下右边的左下箭头,提示词就自动各就各位了。
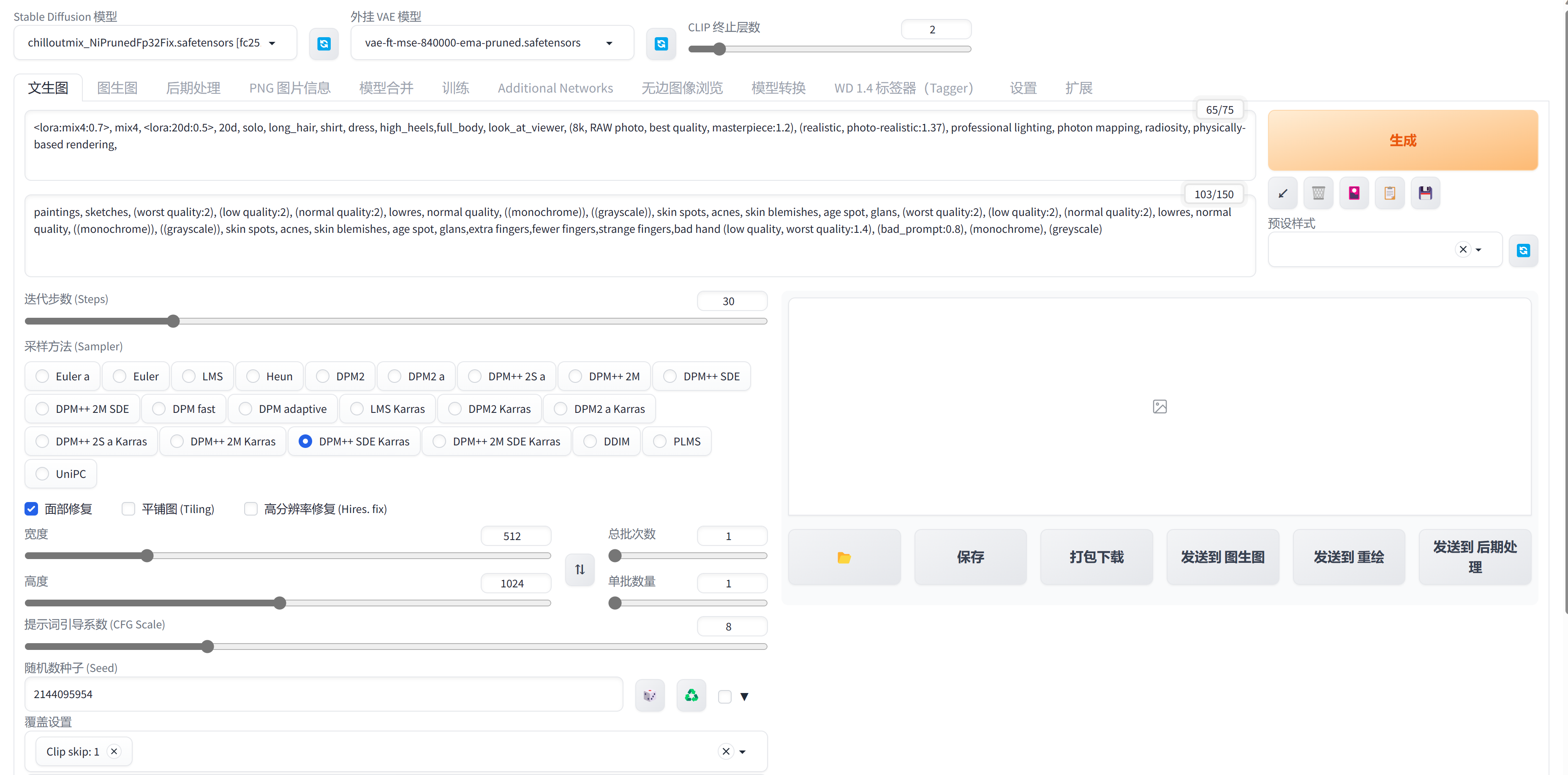
我们大概过一下: 正向提示词前面是模型以及比例,这两个模型就是我们刚刚下载的两个lora模型,你可以调整他们的比例来影响最终效果,这些单词你不认识的话就翻译一下看看,我们先不改 下面的一些配置都是复制过来的,我们把总批次数改为4,直接先生成一个试试。
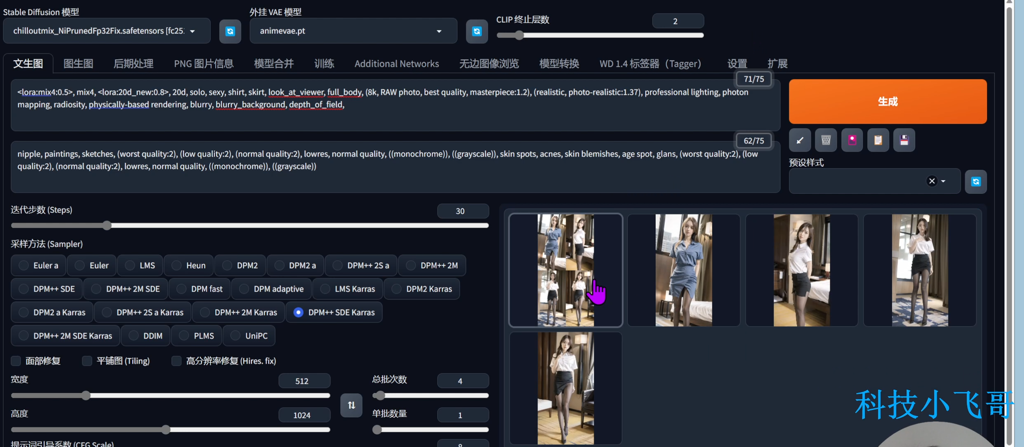
生成效果图如下,如果你对这些都不满意,就修改你的Lora模型的权重,以及修改关键字来调整输出。
图生图
如果你对哪一张满意,可以选定,然后 点击右下角的 发送到图生图,我们以这张图片继续来优化。
我对这几张黑丝大长腿挺满意的,我们选择一张,点击发送到图生图,然后以这个图片再生成图片。
图生图我们依然可以进行提示词优化,我们采样方法要手动调整一下,继续选择刚才的DPM++ SDE Karras,然后总批次数继续选择4,随机种子选择上次的。
我们再加一些提示词,比如你想要大胸,就写 massive breasts,然后点击生成,我就选择中等的胸吧,直接输入medium breasts。太大了就不是可爱风了。

后期处理
我们可以继续选择图生图继续处理。也可以选择涂鸦或者局部重绘,由于篇幅限制我将在下篇讲解高级功能。我们直接当作图片已经完全处理好了点击发送到后期处理。
缩放比例:4
Upscaler 1:SwinlR_4X
Upscaler 2: R-ESRGAN 4x+
放大算法2强度:0.5
GFPGAN强度:0.1
CodeFormer可见度:0.1
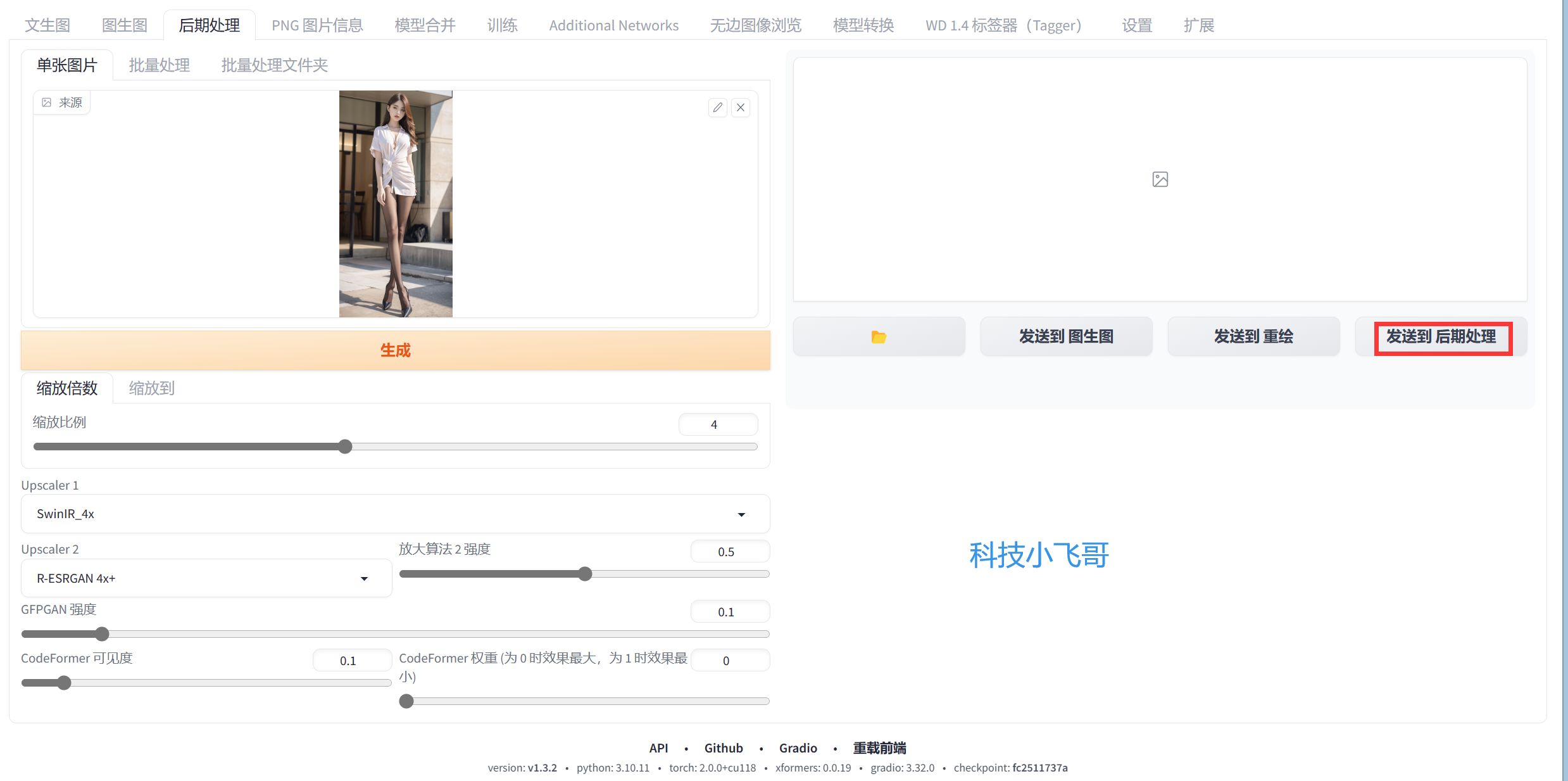
点击生成,等一段时间后,就处理完了,我们看一下细节非常棒,你可以保存下来慢慢欣赏了。
后记
Stable Diffusion光看界面以及那么多模型,我们就知道非常复杂,比如我们自己来通过一定的图片来训练模型。这些我会在后续的教程教大家。这篇教程是纯小白教程,让你从零基础使用Stable Diffusion,可以跟着我的教程通过修改参数能生成你满意的图片。
视频教程
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。